近日,湖南大学电气与信息工程学院刘杰教授课题组自主研制出了“存算一体”非冯·诺依曼类脑芯片架构,用于加速分子动力学高性能科学计算。相较主流Intel CPU、NVIDIA GPU芯片,在保持计算高精度前提下,实现了约2个数量级提速。研究成果以“Accurate and efficient molecular dynamics based on machine learning and non von Neumann architecture”为题,发表在《npj Computational Materials》期刊。第一作者为电气院博士生莫平辉,通讯作者为刘杰教授。

自1946年发明至今,冯·诺依曼架构一直占据统治地位,是CPU、GPU等主流芯片的基础,也是手机、台式机、笔记本、计算服务器、超级计算中心的底层基础架构。目前,需要运行分子动力学等高性能科学计算时,使用冯·诺依曼架构的计算机是几乎所有研究人员的唯一选择,这已成为一种“固有范式”(paradigm)。遗憾的是,冯·诺依曼架构中,计算单元(例如CPU/GPU)和存储单元(例如内存)是互相独立的(即“存算分离”),导致计算总耗时和计算总功耗中的绝大部分(>90%)消耗于存储单元、计算单元之间的频繁数据搬运,俗称“存储墙(memory wall)”和“功耗墙(power wall)”瓶颈。这严重制约了计算性能的提升。
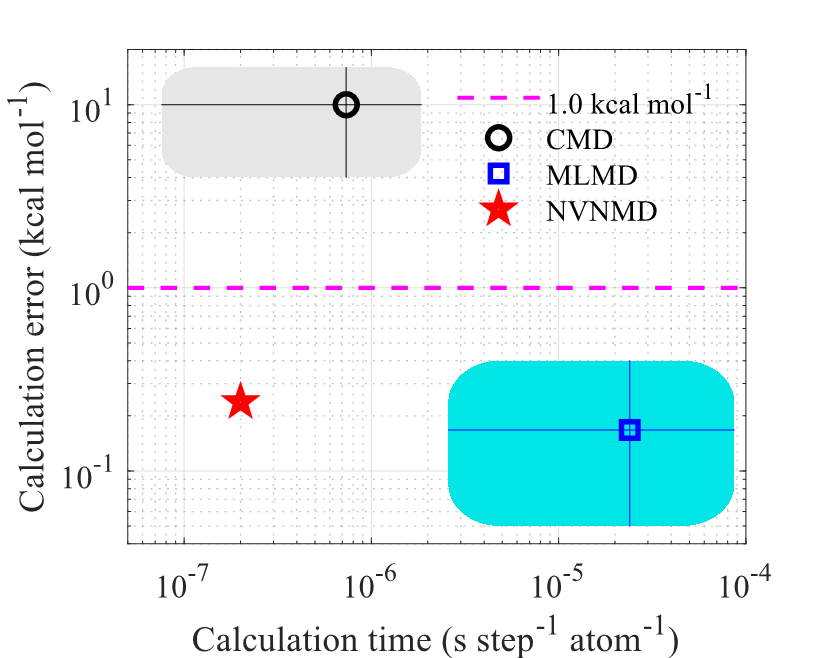
为解决该问题,刘杰教授团队自主设计了“存算一体”的类脑芯片架构,并基于FPGA研制出了基于新型非冯·诺依曼芯片架构的分子动力学计算系统“NVNMD”(第一版),实现了从传统冯·诺依曼芯片架构向新型非冯·诺依曼芯片架构的“范式转移(paradigm shift)”。NVNMD的核心计算模块中,存储单元和计算单元紧密融为一体(即“存算一体”),避免了频繁的数据搬运,极大缓解了计算中的“存储墙”和“功耗墙”瓶颈。实测表明,相较主流CPU、GPU等传统冯·诺依曼架构芯片,可将计算速度提升大约2个数量级;并可将计算功耗降低大约3个数量级。
长期以来,受制于冯·诺依曼芯片架构内禀的“存储墙”等瓶颈,在“速度”和“精度”这两个核心指标上,分子动力学存在“鱼与熊掌不可兼得”的问题——经典分子动力学(classical molecular dynamics, CMD)速度快,但精度低,难以满足高精度计算要求;第一性原理分子动力学(ab-initio molecular dynamics, AIMD)精度高,但速度慢,难以计算大系统。该成果提出的新型NVNMD兼具AIMD级别的高精度、CMD级别的高速度,在物理、化学、生物、制药、地质、材料、半导体、纳米技术等领域有广泛应用前景。
目前,该团队正在基于高端工艺节点,设计非冯·诺依曼架构ASIC芯片的NVNMD(第二版),旨在实现单节点(平方cm量级芯片、百瓦量级功耗、新型非冯·诺依曼芯片架构)分子动力学算力大致相当于美国最强超算中心Summit算力总和(占地一栋楼、十兆瓦量级功耗、传统冯·诺依曼芯片架构)的研究目标。
本研究成果相关的资源链接:
论文链接:https://www.nature.com/articles/s41524-022-00773-z
训练代码:https://github.com/LiuGroupHNU/nvnmd
计算服务:http://nvnmd.picp.vip
来源:电气院
责任编辑:文亦佳




 【组图】2024年研究生师生篮球联赛、啦啦操比赛举行
【组图】2024年研究生师生篮球联赛、啦啦操比赛举行
 【组图】湖南大学2024级新生报到
【组图】湖南大学2024级新生报到
 【组图】毕业快乐,前“图”似锦
【组图】毕业快乐,前“图”似锦